Italian Version | English Version
1. Finding documents in ELA
1.1 Document List
1.2 Search
1.3 Browse
2. Document viewer
3. Information about the document
4. ELA Tools
4.1 Stats and analysis of a document
4.2 Analysis of corpora
1. Finding documents in ELA
1.1 Document List
It consists of a list of documents (author, title) in alphabetical order by name of authors.
1.2 Search
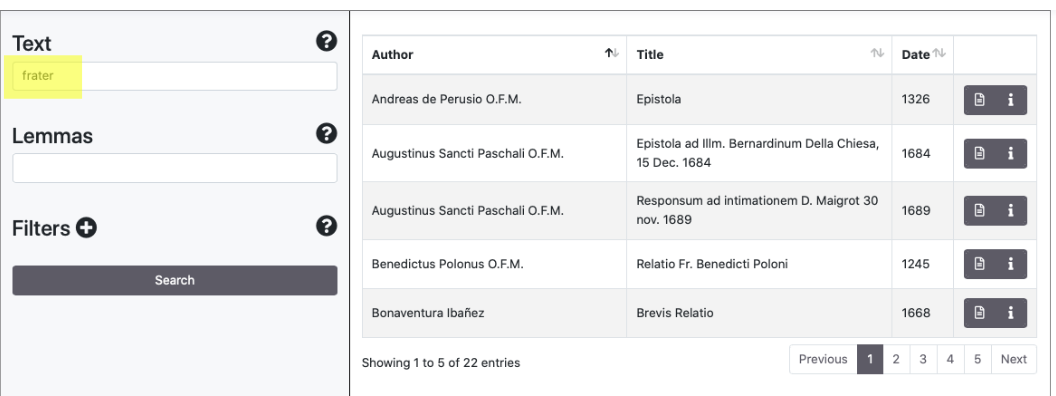
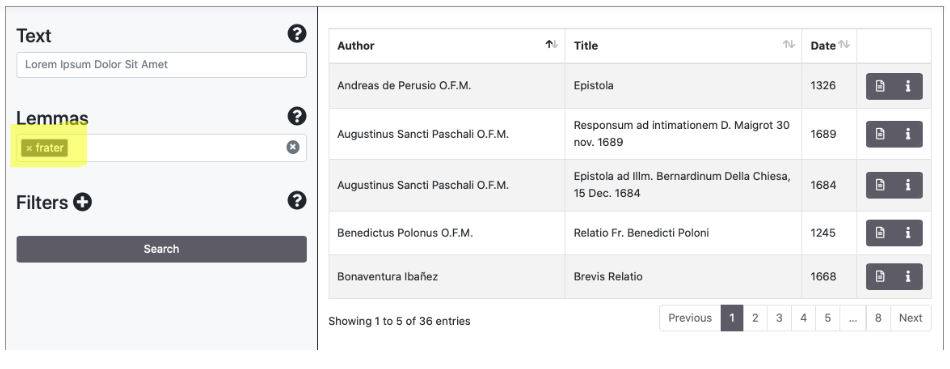
The Search panel allows to search documents via a search engine based on words and lemmas. It is possible to perform queries using the Lucene syntax and combine researches with filters. Some examples:
Simple queries
In the results panel documents are listed by default in alphabetical order sorted by Author. By clicking on the arrows near Author, Title and Date it is possible to modify the sort order. The entire document list can be traversed by means of the Previous/Next buttons. The entire number of documents found is shown at the end of the list.
Query for Strings
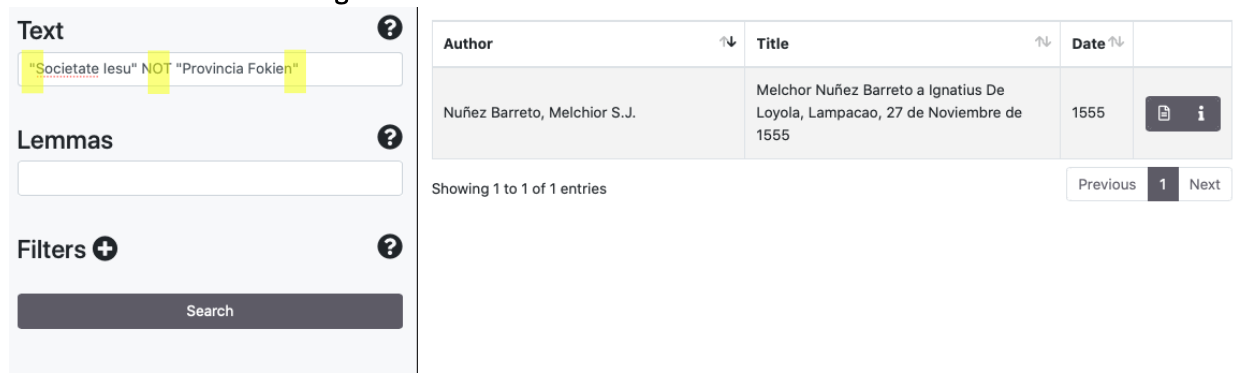
The Exact Match of a sequence of words is available using quotation marks [" "].
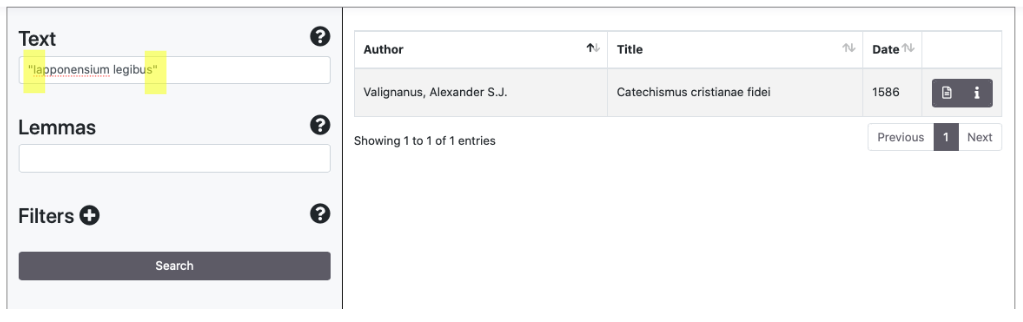
Query with filters
Filters can be used by clicking the symbol [+]. They allow to include (has) and to exclude (has not) values filtered by keys (author, title, date of the document, places/people/dates mentioned in the document, a generic georeferentiation of the document). The search engine suggests possibilities for the completion of the words filtered.
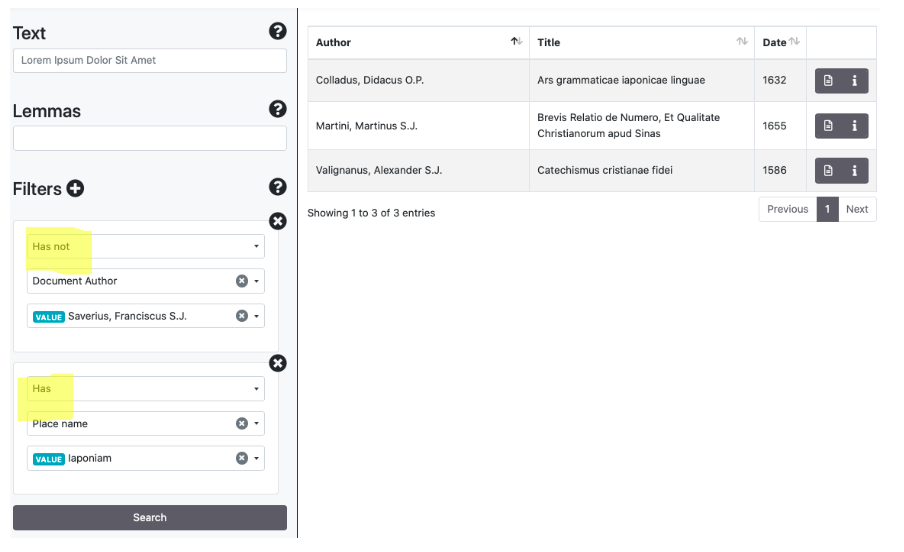
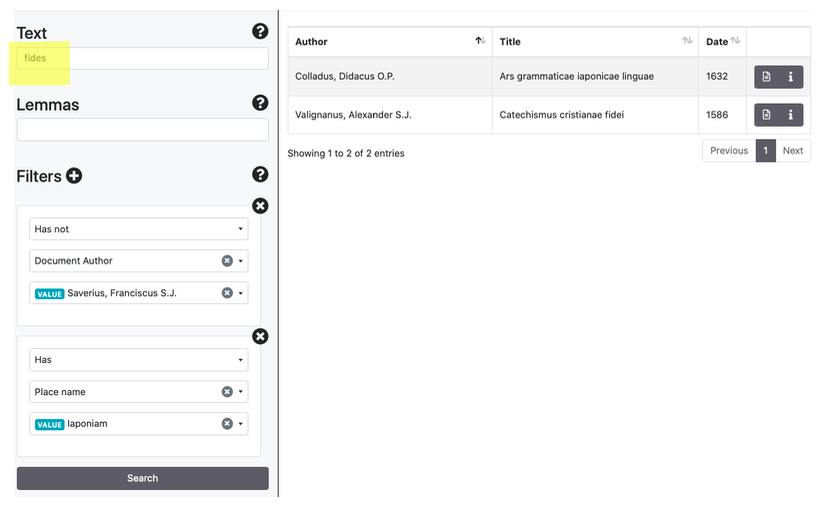
Wildcards
In the Text field, it is possible to perform wildcard search for a single character by means of the symbol [?] and multiple characters via the [*] symbol.
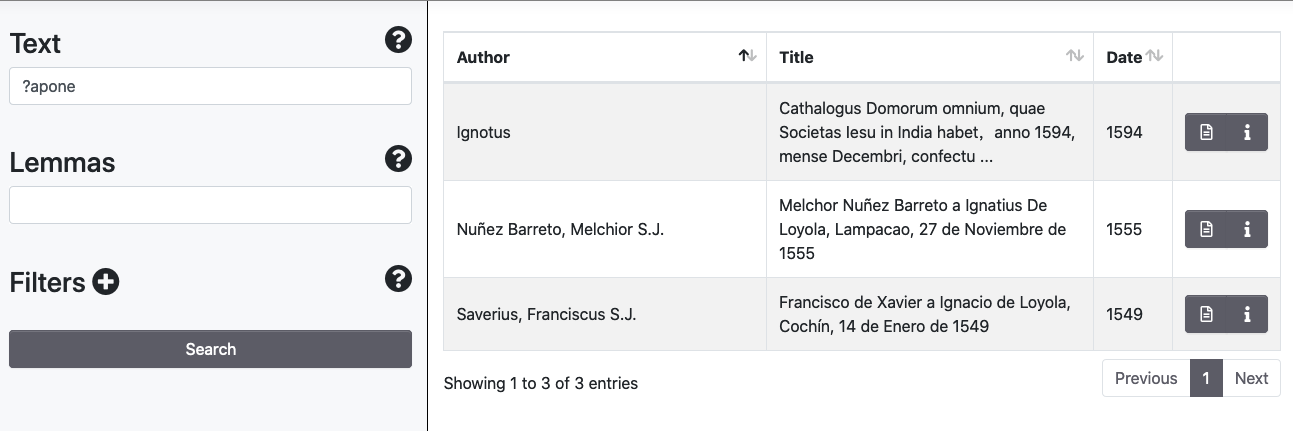
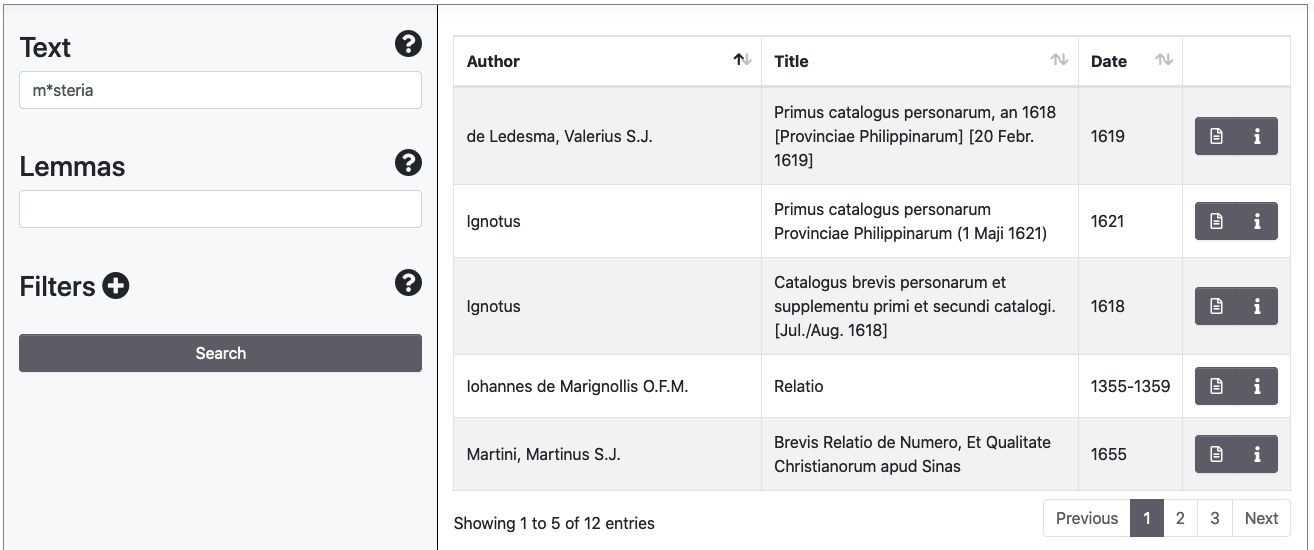
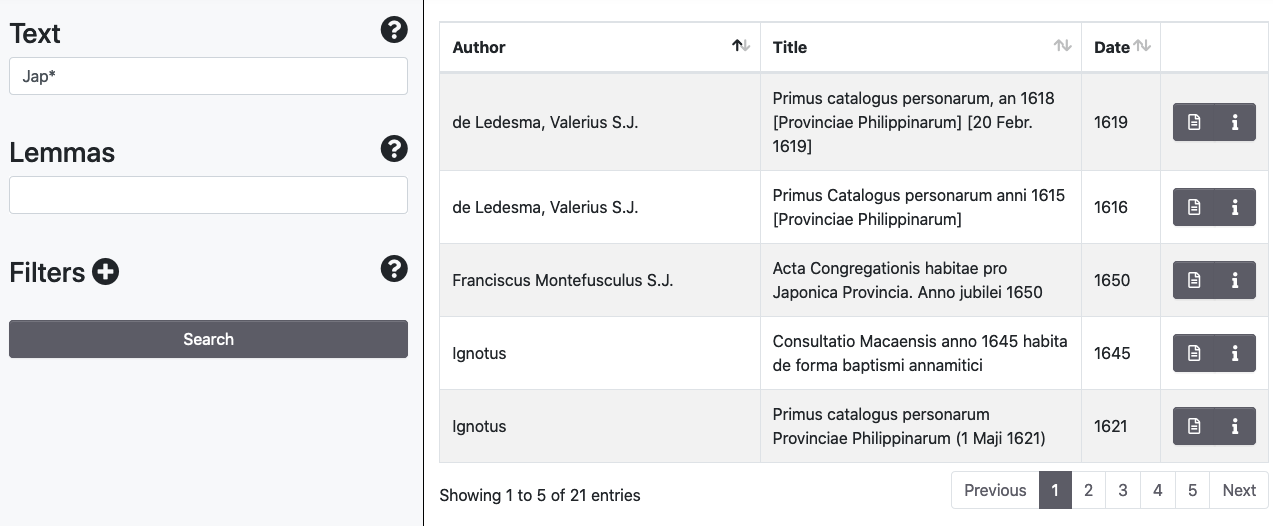
Levenshtein Distance and Proximity Searches
It is possible to perform fuzzy searches using the tilde symbol [~], with the default parameter of 0.5
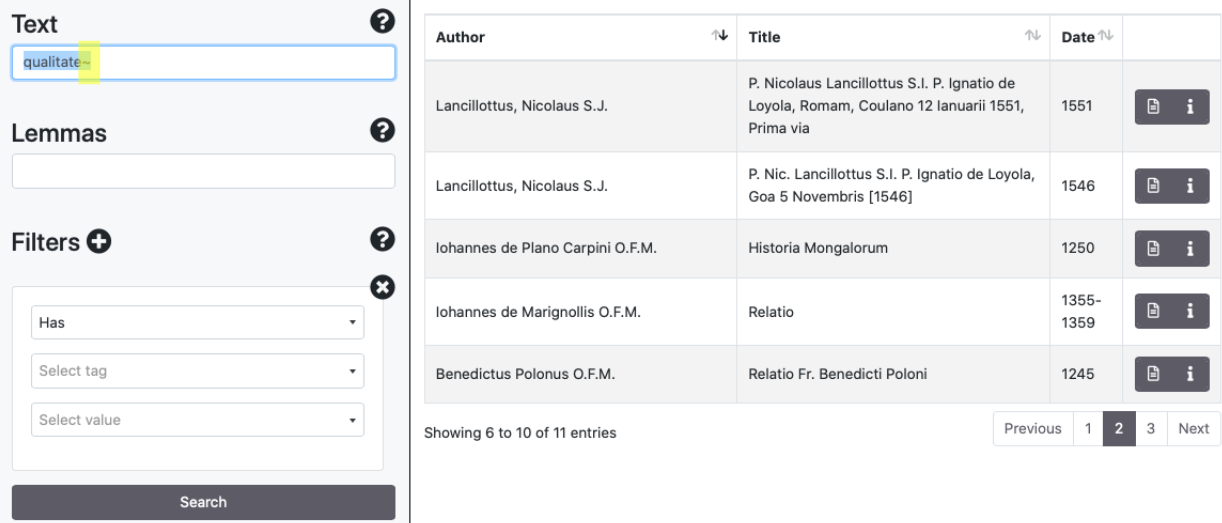
To perform Proximity Searches it is possible to search two values [" "] using the symbol tilde [~] followed by the maximum distance in terms of words.


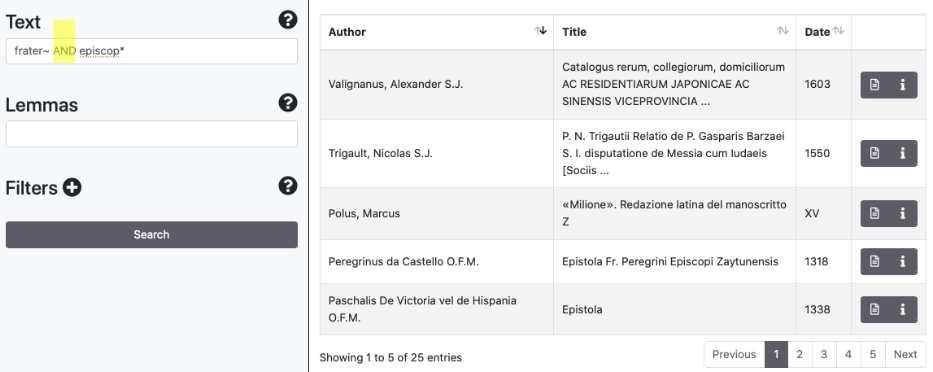
Boolean Operators
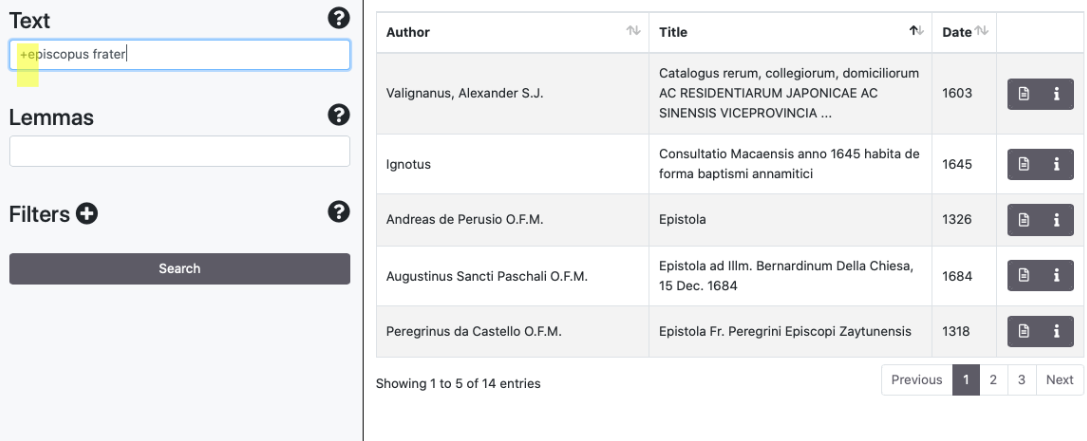
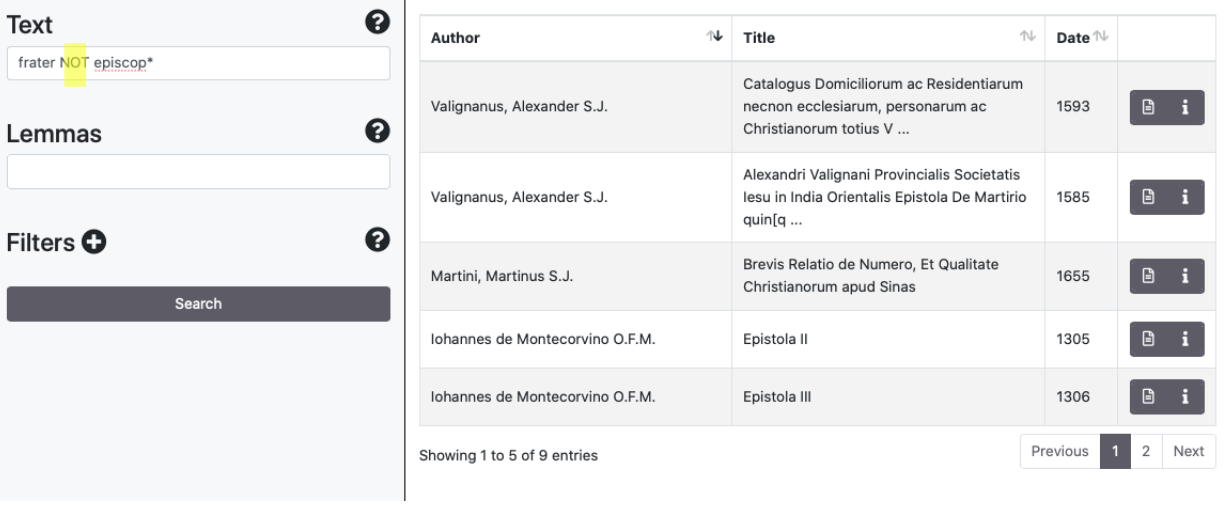
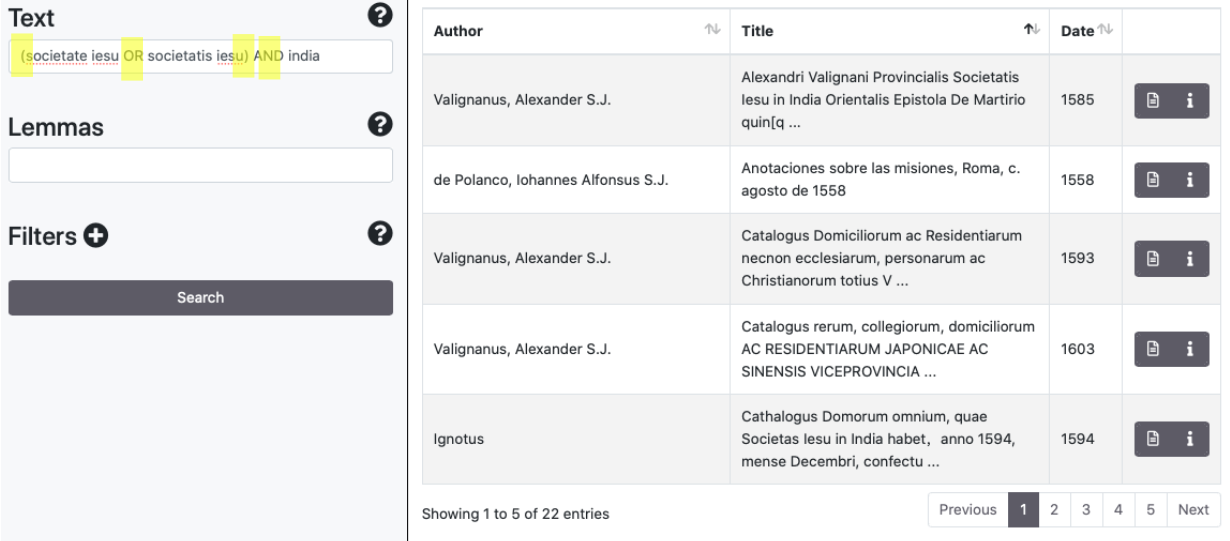
The search engine supports Boolean Operators such as AND/&&, [+], OR, NOT/[-]. Some examples:
1.3 Browse
The Broswe panel allows to explore the archive by showing lists of documents indexed by metadata. It is possible to browse the archive via the following indexes:
- Authors
- Places mentioned in the text (if encoded in XML/TEI)
- People mentioned in the text (if encoded in XML/TEI)
- Date of the document
- Type of document (prose/poetry)
- The title of the edition or edited collection, if it is present (i.e. Documenta Indica, Sinica Franciscana)
- Genre (i.e. Ars Grammatica, Epistolae, Itinera et Relationes)
- Geographic reference: it is a generic reference related to the document (i.e. China, India)
- Language: languages used in the document (usage percentage is mentioned in the TEI Header of the XML document)
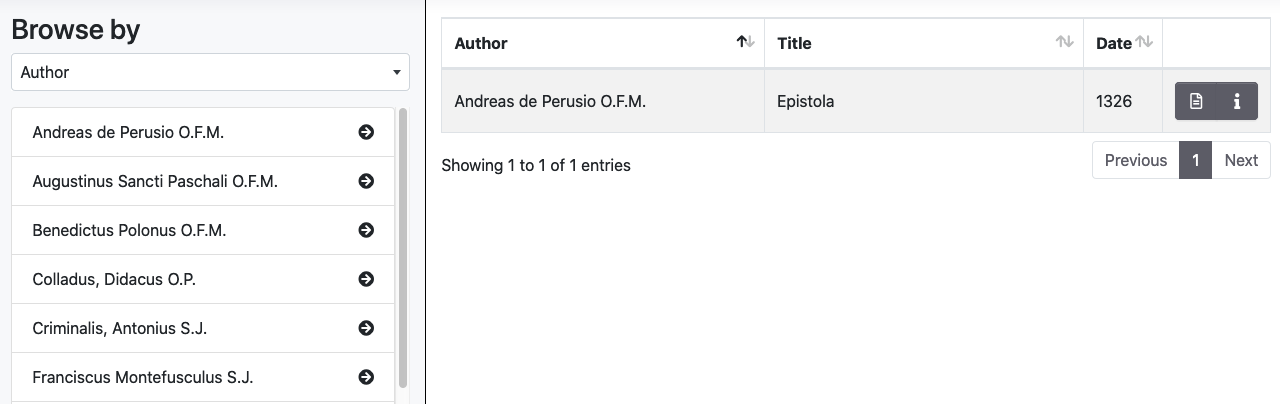
2. Visualisation of the document
Access to the item
From the Document List it is possible to view the document through the arrow icon near the title

From the Search and the Browse panels the document viewer is accessible by clicking the document icon

Document Viewer

The Info panel shows essential metadata related to the document. The Menu panel allows to modify part of the default settings (disable the page/folio break indication, highlight of tags, document background) and to download texts in the TXT, XML and PDF formats.
The header of the documents reports the Title, the name of the author (linked to a VIAF or Wikidata reference when present), the dates of birth and death of the author, and the edition used (linked to WorldCat).
The document contains some tags: by hovering the cursor on the underlined words, a pop-up window shows the related types of tag (Place/Date/Person) and a normalized form of the tags.



3. Information about the document
Metadata related to an item are available by clicking, on the Browse and Search panels, the Info icon:

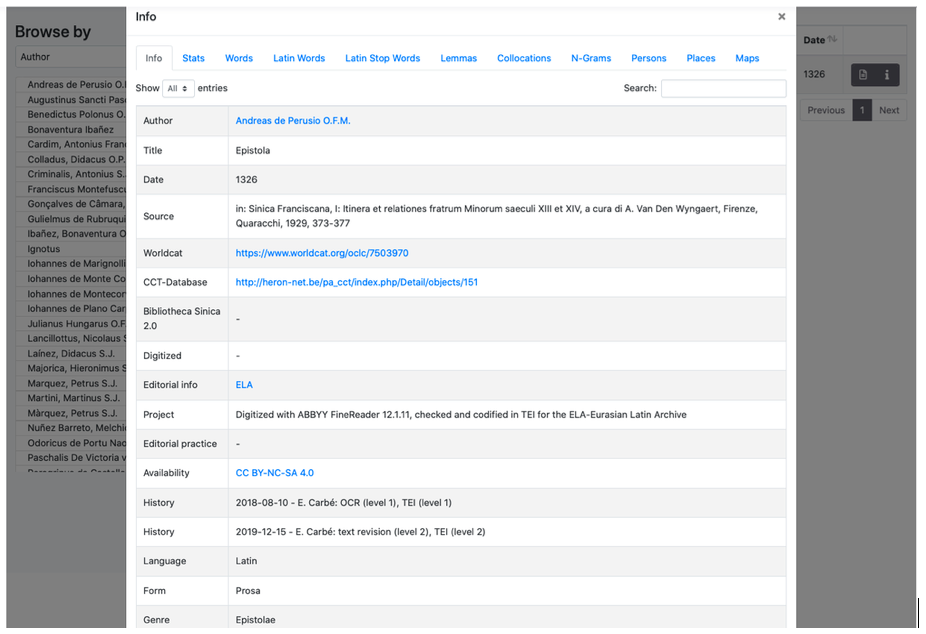
Metadata related to author, title, date, reference to the edition used to contain a link to WorldCat and, if present, links to CCT - The Chinese Christian Texts Database e Bibliotheca Sinica 2.0.
If the original source is scanned and available online, a link is provided in the Digitized section.
Information about the Project and Editorial Practices are provided under the appropriate entries.
Availability refers to the licence used to publish a document in ELA. ELA provides texts under the Creative Commons BY-NC-SA 4.0. ocuments provided by other projects and digital archives/libraries (i.e. ALIM, Corpus Corporum, Gutenberg Project), keep the original licence and could in some cases be subject to copyright.
The History entry reports about the history of the document into the ELA processes and the authors of changes. Documents in ELA have to pass a quality control process that ends with the assignment of a quality level (from 1 to 3) depending on the reliability of the transcription and the quality of XML/TEI encoding.
- Quality of transcription: a document with a level 3 has been revised at least by three editors and is considered highly reliable. Level 2 means that the text has been checked only by an editor. Level 1 if for texts which could have more than a misprint.
- Quality of TEI: level 3 is only given to a manual revision of the semantic TEI part (name of places, people, dates); level 2 means that the TEI has been manually encoded or at least checked, and the semantic part of the TEI has been processed automatically by the Retag utility available withi the ELA-Toos. Level 1 is a non-optimal TEI encoding from a structual and/or semantic point of view.
4. ELA Tools
ELA has developed some tools that are available on GitHub. They consist of tools that extract information from the XML files and perform operations such as automatic TEI tagging, Jupyter notebooks that can be used for cleanup and normalization of documents and texts analysis, as well as other utilities. The main tool, based on CLTK and NLTK, has been integrated into the platform ELA to perform statistics and linguistic/semantic analysis on the documents.
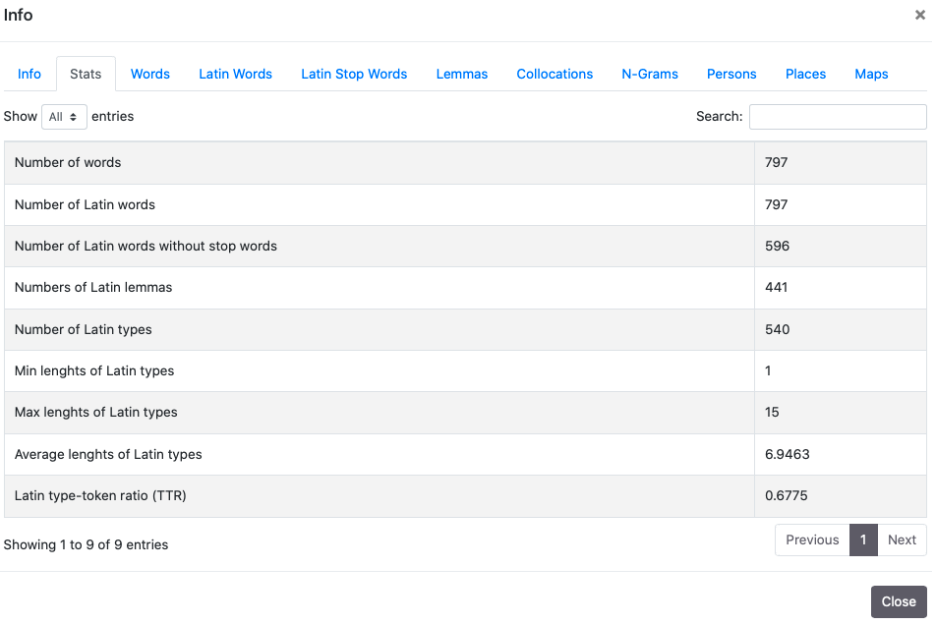
4.1 Stats and analysis of a document
From the Info panel it is possible to access sections devoted to statistics and analysis of documents:
- Stats
- Numbers of words and Latin words of a document (if the document is not multilingual the number is obviously the same)
- Number of Latin words without stop words
- Number of Latin lemmas identified by the CLTK lemmatizer
- Number of Latin types
- Max/min/average lengths of Latin types
- Latin Type/Token Ratio (TTR)
2. Words and Latin Words
In these sections, it is possible to find frequencies of types. It is possible to sort results in alphabetical order (Word) or in Frequency/Percentage order, ascending or descending. The two sections show by default the first five occurrences ordered by Frequency. It is possible to modify the number of shown occurrences using the “Show” drop-down menu and to use the Search module to look for words and parts of the word. If the document is multilingual the two sections are identical.
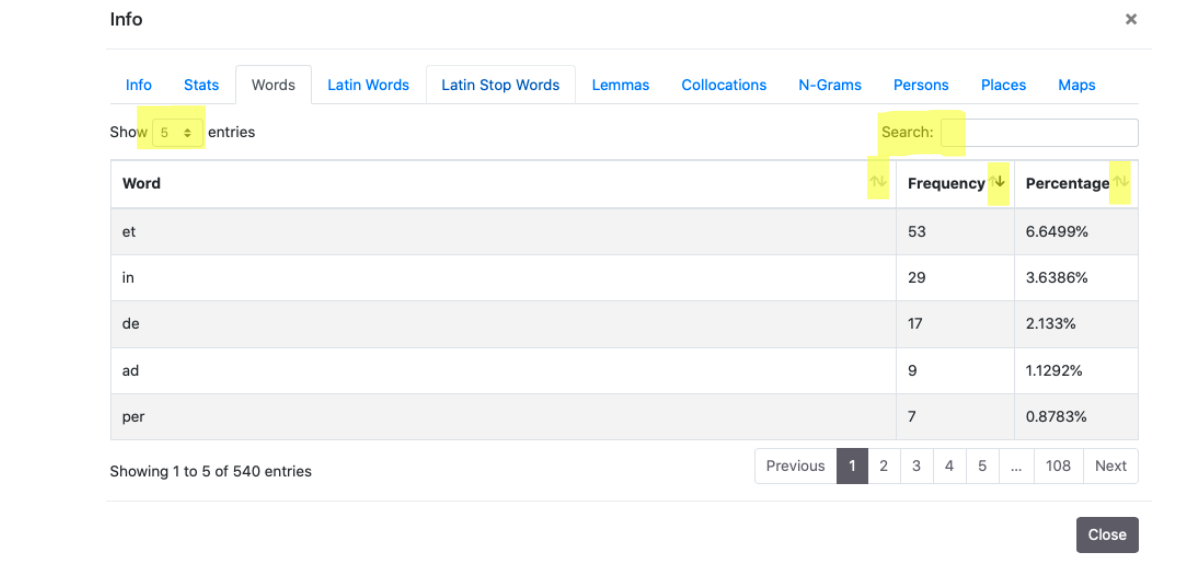
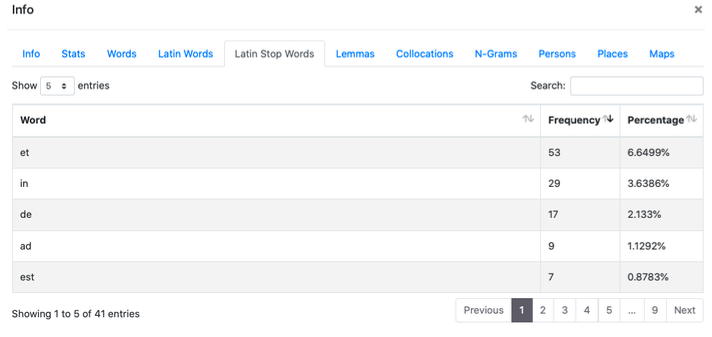
3. Latin Stop Words
In this section, analogous to the two previously explained ones, there is an index of frequencies of the following stop words: ab, ac, ad, adhuc, aliqui, aliquis, an, ante, apud, at, atque, aut, autem, cum, cur, de, deinde, dum, ego, enim, ergo, es, est, et, etiam, etsi, ex, fio, haud, hic, iam, idem, igitur, ille, in, infra, inter, interim, ipse, is, ita, magis, modo, mox, nam, ne, nec, necque, neque, nisi, non, nos, o, ob, per, possum, post, pro, quae, quam, quare, qui, quia, quicumque, quidem, quilibet, quis, quisnam, quisquam, quisque, quisquis, quo, quoniam, sed, si, sic, sive, sub, sui, sum, super, suus, tam, tamen, trans, tu, tum, ubi, uel, uero, unus, ut.
4. Lemmas
Ela uses the lemmatizer CLTK (Backoff Method). To try the lemmatizer Lexicon (lexicon.unisi.it) it is possible to download the ELA corpus in txt format from GitHub.
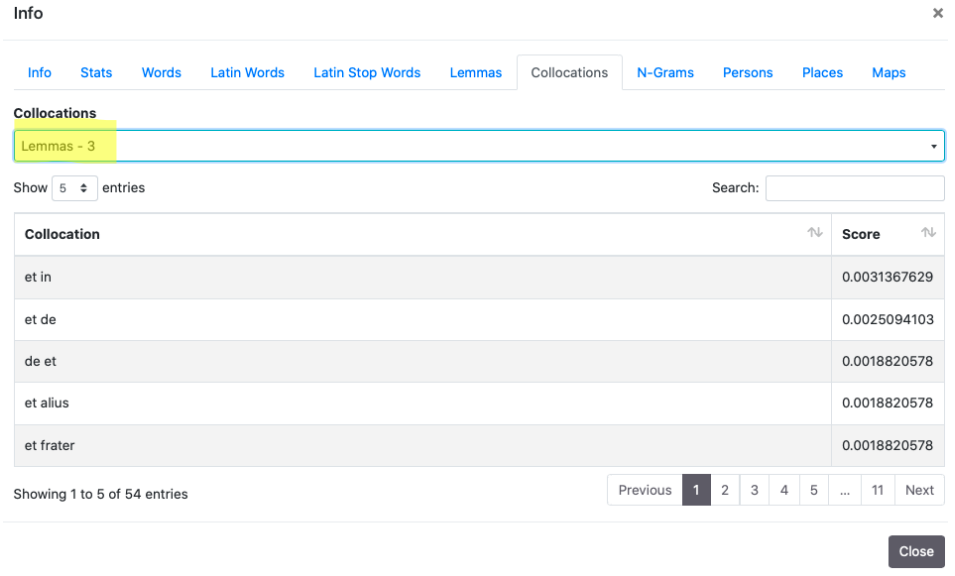
4. Collocations
It is possible to perform researches into a range 1-5 both on words and lemmas, using the field “Search” and verifying the score near the Collocation. See the documentation on the appropriate section of NLKT.
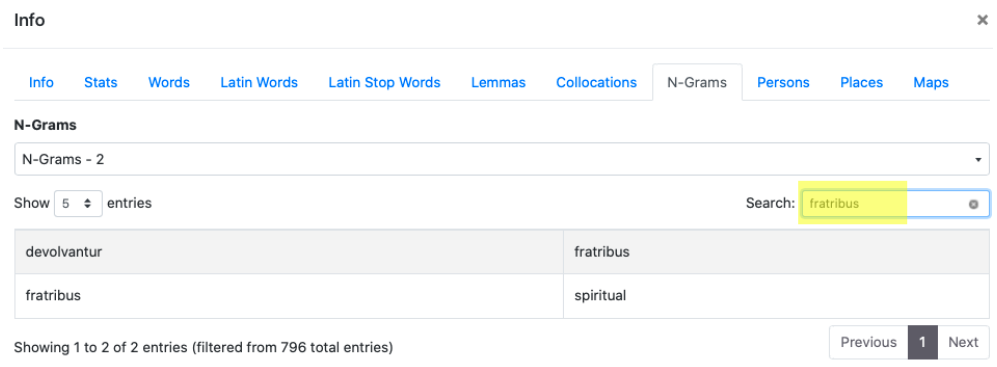
4. N-grams
N-grams (from 2 to 5) show sequences of words that can be searched using the Search module
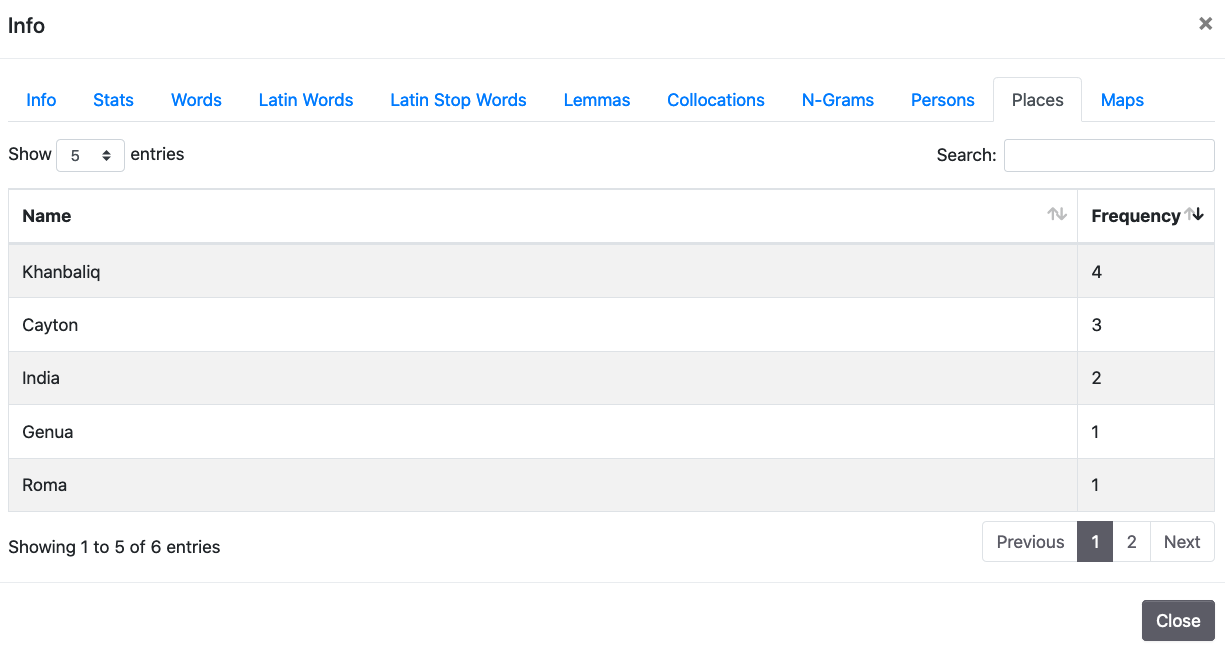
5. Person/Place
These two sections expose indexes of frequencies of place names and people names found in documents. Please notice that the list could be incomplete if documents do not reach level 3 of TEI quality.
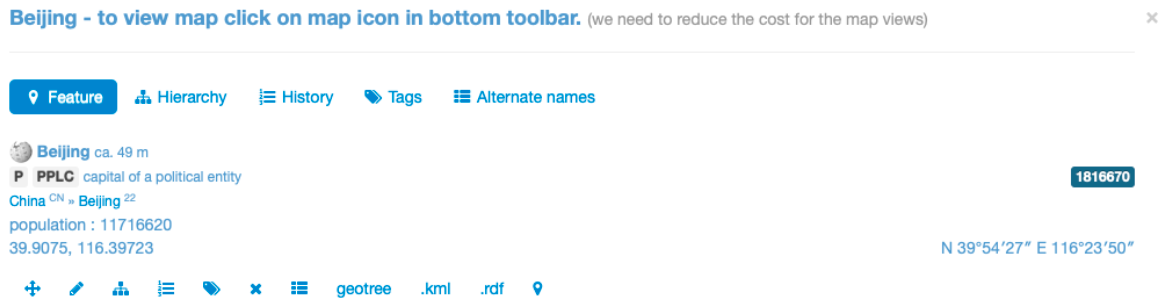
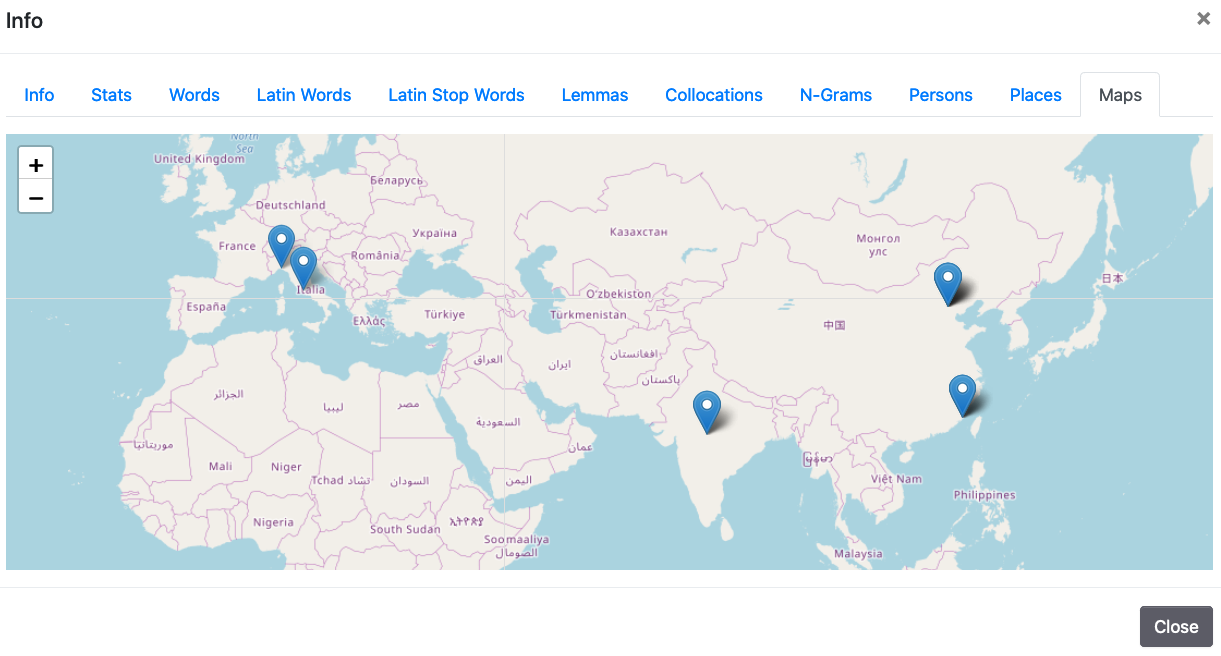
6. Maps
Maps, based on Leaflets, show the geolocalization of place names that have been identified using Pleiades and GeoName. As said for the indexes of place names and people names it has to be taken into account that information might be incomplete and some places identified in the text might not appear on the map. By clicking on the placeholders, a pop-up window shows the normalized name of the place and the forms used in the texts.
4.2 Analysis of corpora
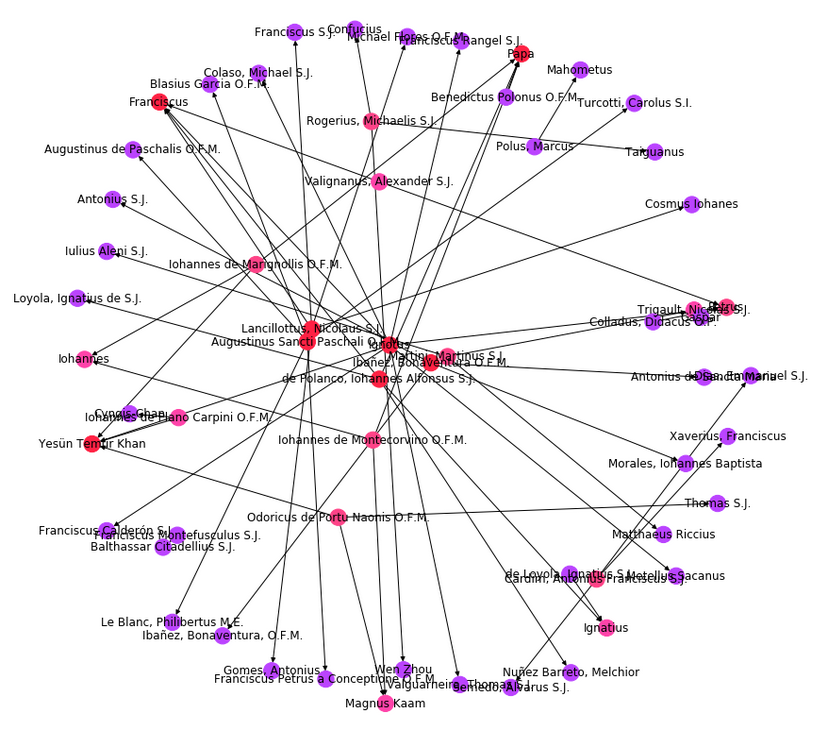
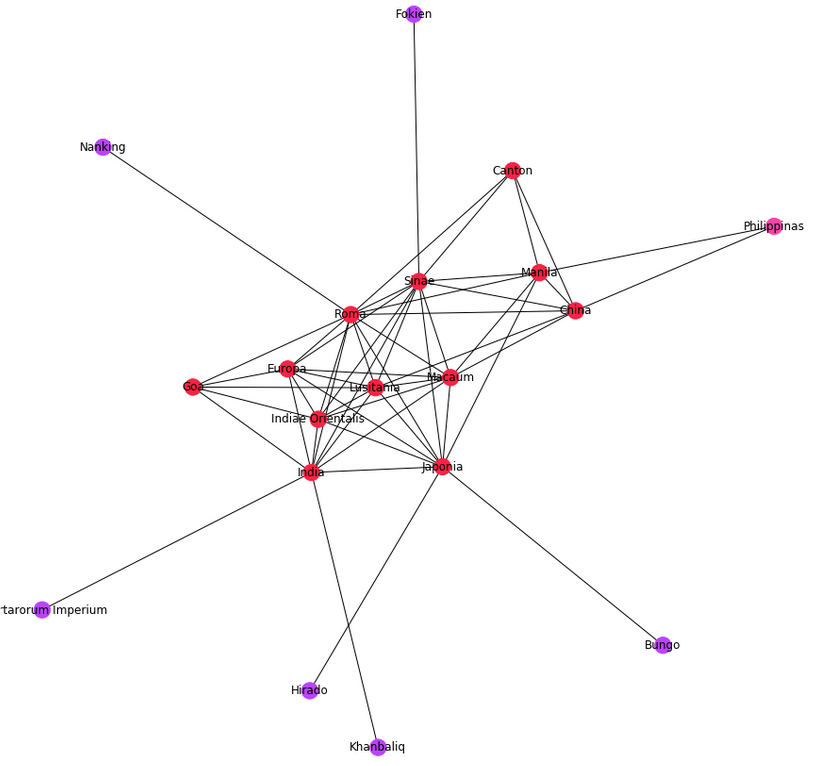
It is possible to perform analysis on the entire corpus or subcorpora of ELA by using the GlobalStats tool published, along with its documentation, on GitHub here. It is available as a Jupyter notebook that also includes some examples of word clouds and network analysis.