Italian Version | English Version
1. Cercare documenti in ELA
1.1 Document List
1.2 Search
1.3 Browse
2. Visualizzazione del documento
3. Informazioni sulla risorsa
4. ELA Tools
4.1 Statistiche e analisi sul documento
4.2 Statiche e analisi del corpus e di subcorpora
1. Cercare documenti in ELA
1.1 Document List
Si tratta di un elenco dei documenti (autore, titolo) con ordinamento alfabetico per autore.
1.2 Search
Il pannello Search consente di cercare documenti attraverso un motore di ricerca basato su parole e lemmi. È possibile utilizzare la sintassi Lucene e combinare le ricerche con dei filtri. Alcuni esempi:
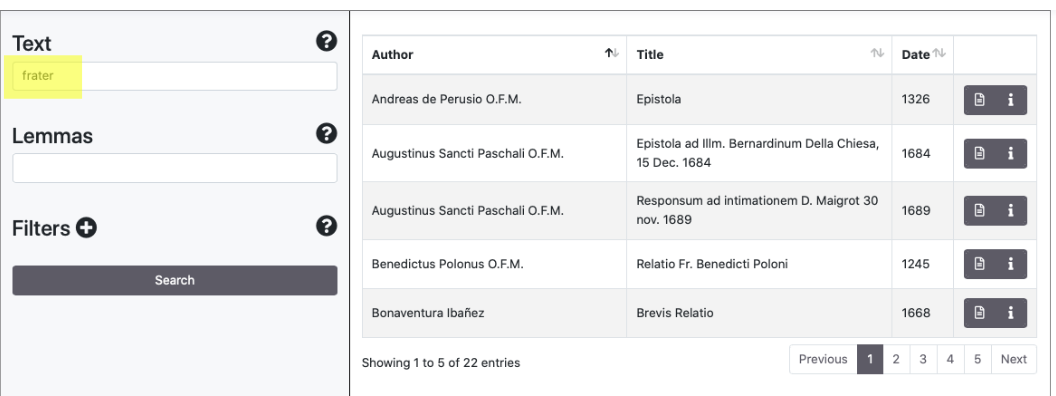
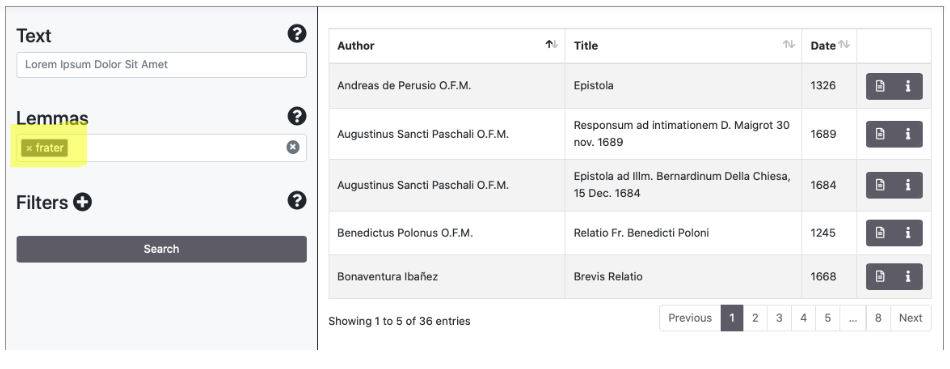
Ricerca semplice utilizzando i campi Text/Lemmas
Nel pannello dei risultati compaiono i documenti in ordine alfabetico per autore. Cliccando le frecce accanto a Author, Title e Date è possibile modificare il criterio di ordinamento. La lista di documenti è navigabile con i tasti Previous/Next. Il numero di documenti trovati è verificabile nella parte inferiore del pannello (entries).
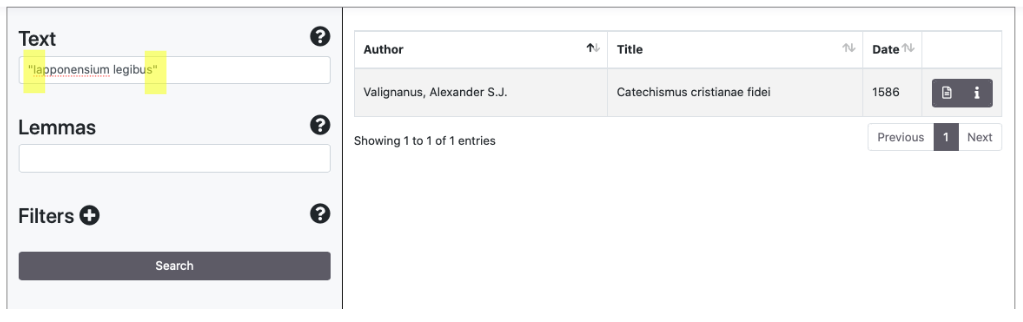
Ricerca di stringhe
La ricerca esatta di più parole viene realizzata tramite l'utilizzo di virgolette (" ")
Ricerca con filtri
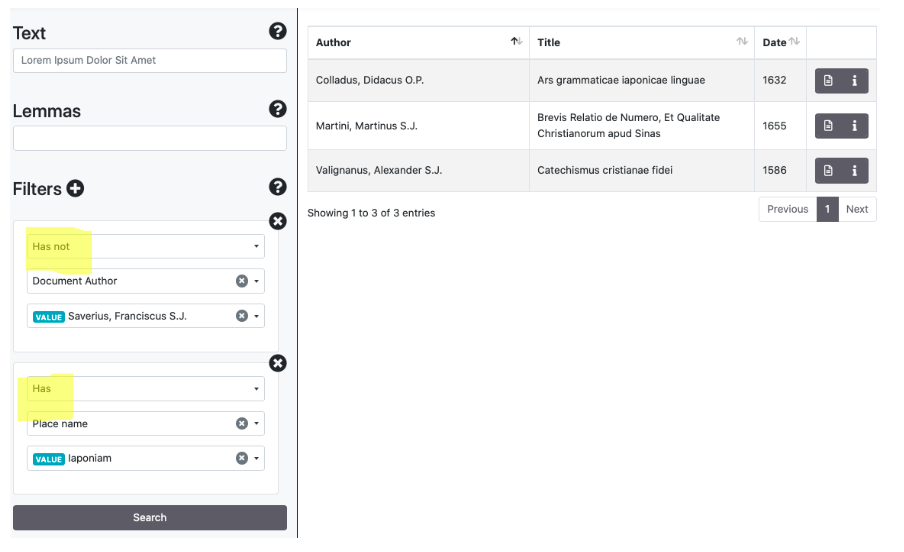
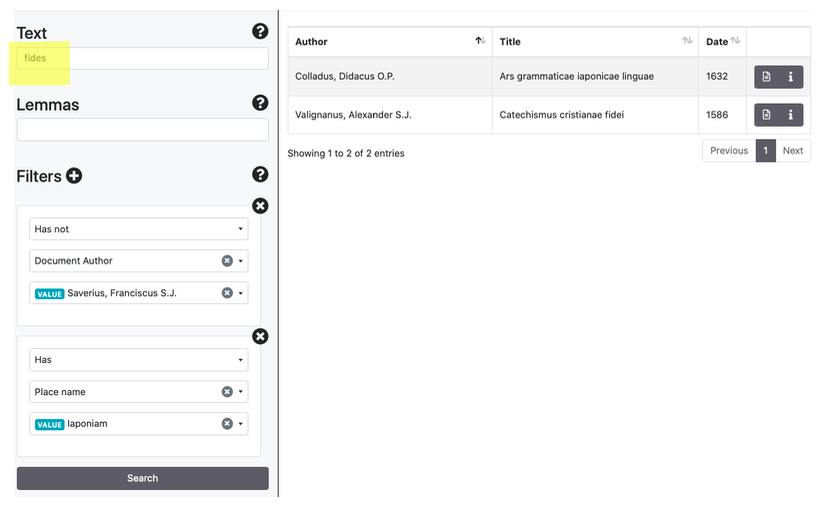
I filtri, attivabili cliccando il simbolo (+) accanto a Filters, permettono di selezionare (has) o escludere (has not) tutti i valori vincolati ad alcune chiavi (autore, titolo, data del documento, luoghi/persone/date menzionati nel documento, georeferenziazione generica del documento). Il sistema suggerisce il completamento automatico della parola digitata in base alla lista di type indicizzati nell'archivio.
Wildcards
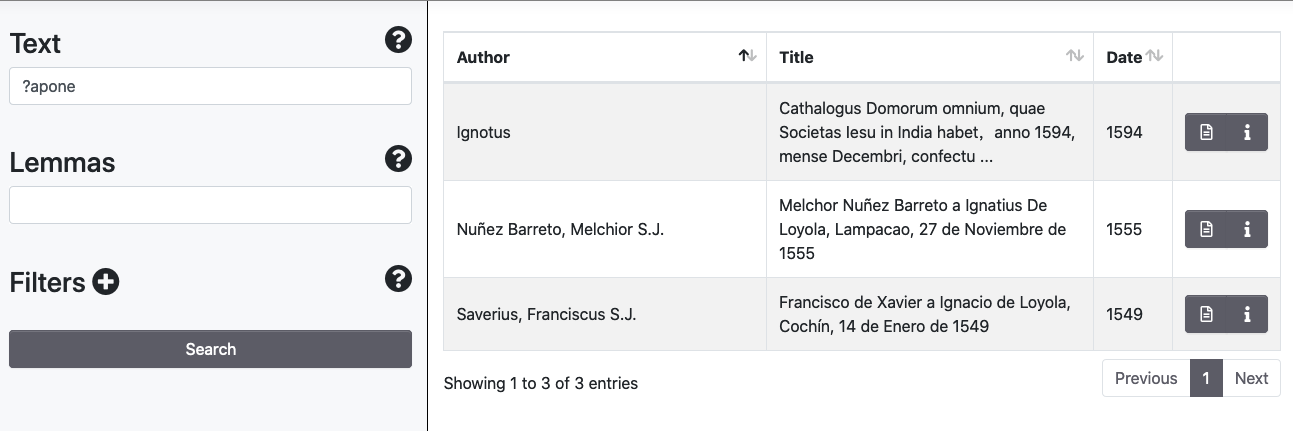
Nel campo Text si possono utilizzare i caratteri jolly punto di domanda (?) per la ricerca di un singolo carattere, e asterisco (*) per la ricerca di caratteri da due a molti.
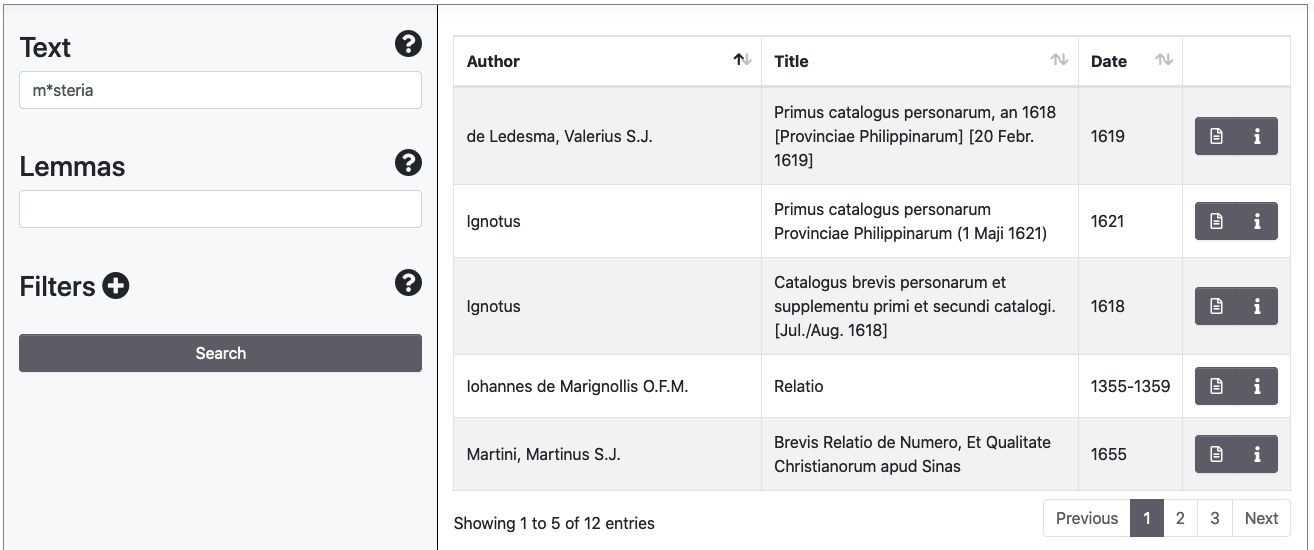
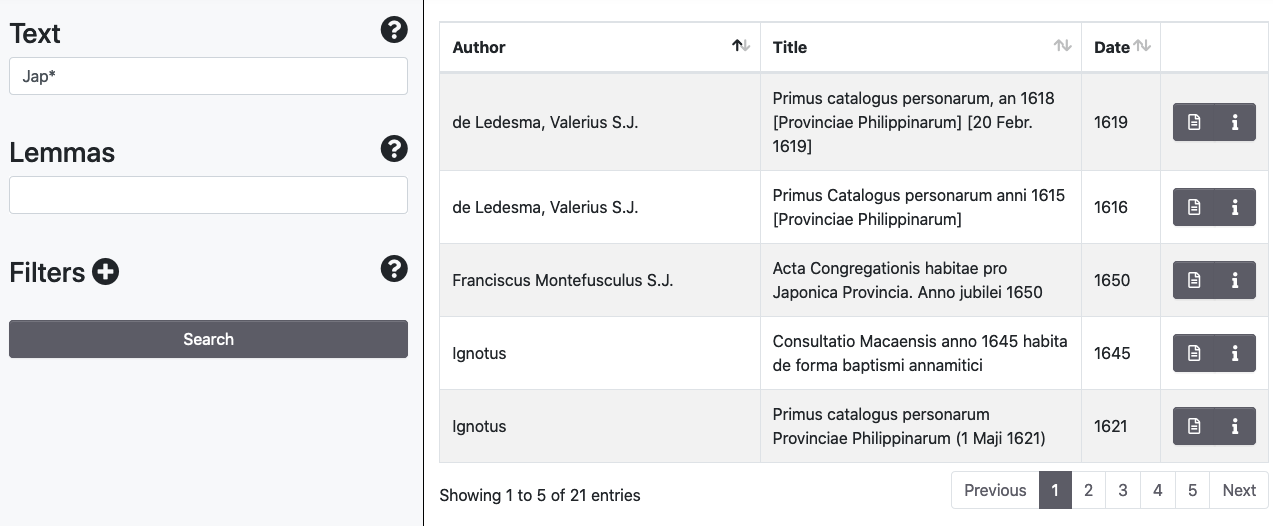
Distanza di Levenshtein e ricerche di prossimità
Con il simbolo tilde (~) è possibile lavorare sulla distanza di Levenshtein (parametro di default 0.5)
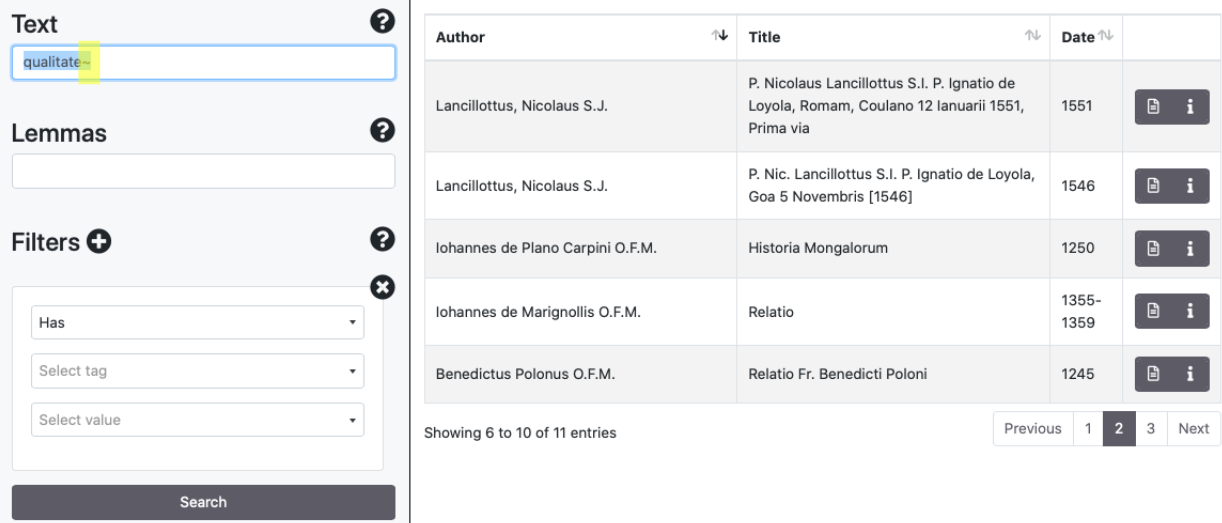
Per eseguire ricerche di prossimità inserire due parole tra virgolette accompagnate dal simbolo tilde e dalla distanza massima di ricerca


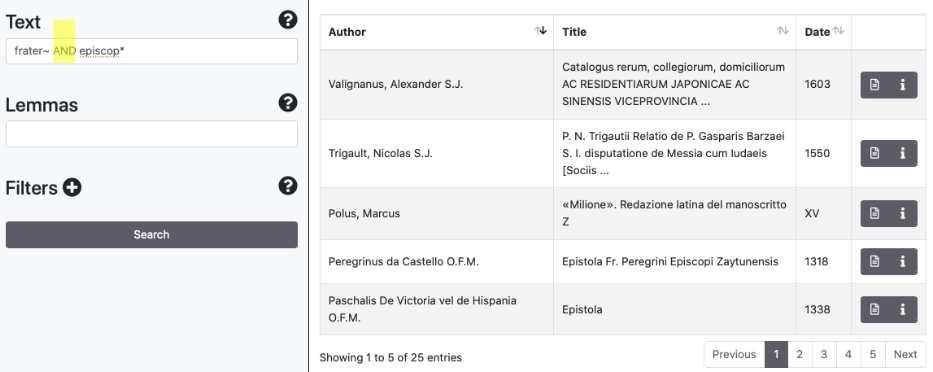
Operatori booleani
Sono supportati gli operatori logici AND/&&, (+), OR, NOT/(-). Alcuni esempi:
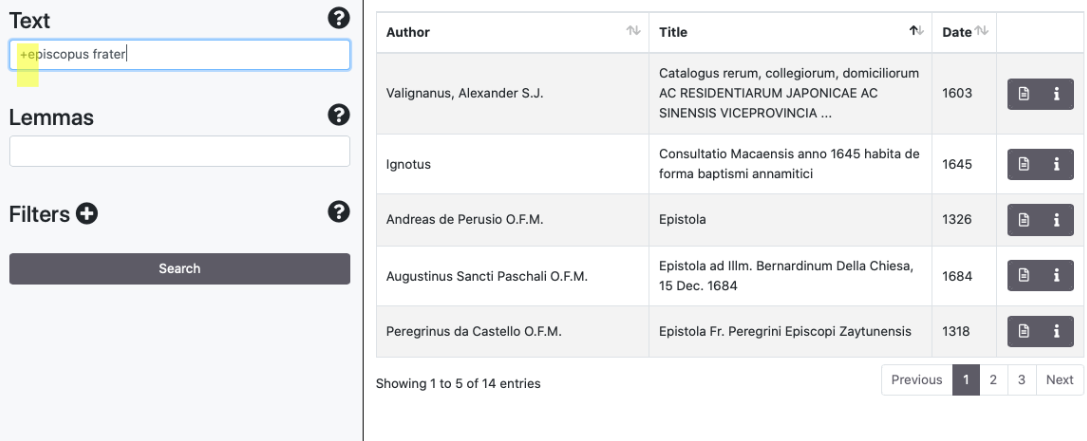
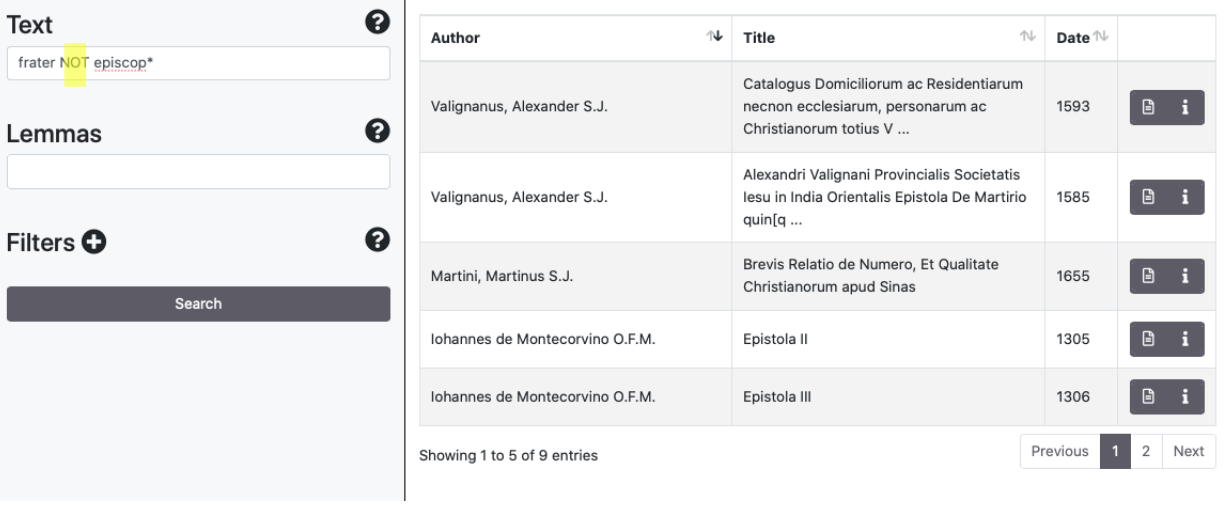
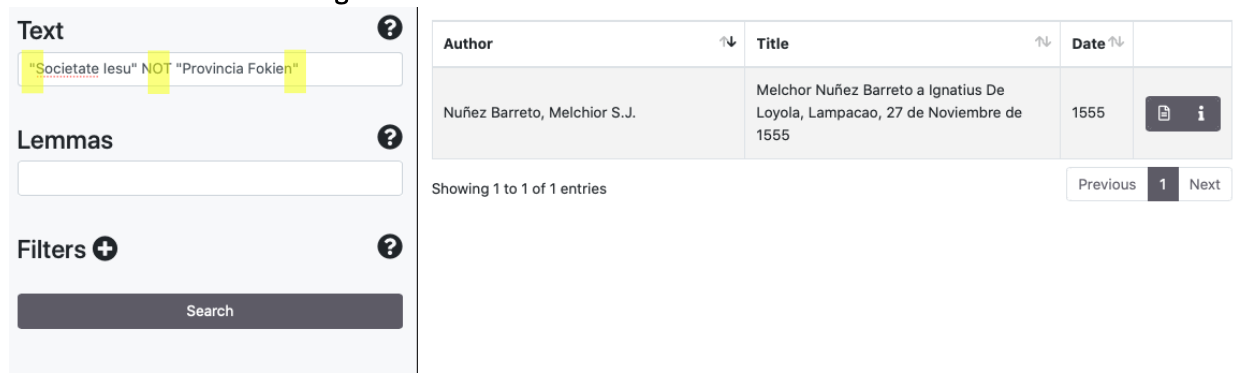
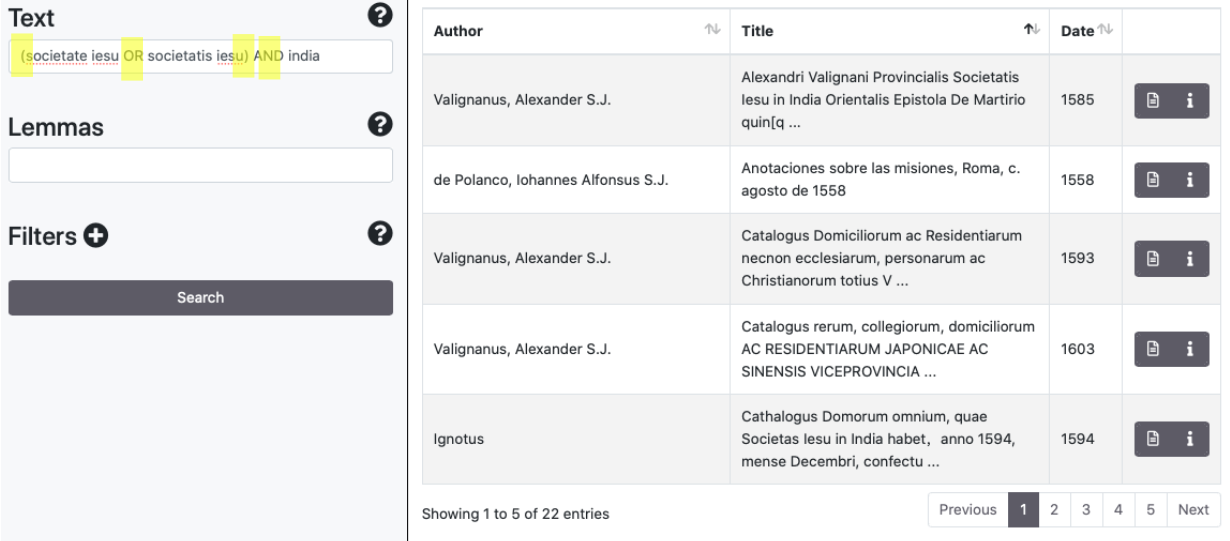
1.3 Browse
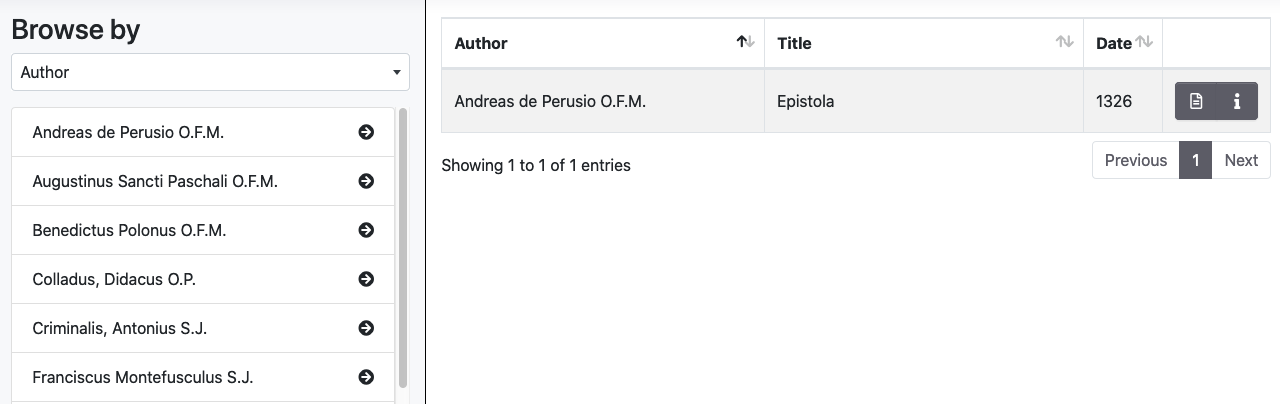
Il pannello broswe permette di esplorare l’archivio tramite liste di documenti aggregati in base ad alcuni metadati. Si può navigare attraverso i seguenti indici:
- Autori
- Luoghi menzionati nel testo (se marcati in XML/TEI)
- Persone menzionate nel testo (se marcate in XML/TEI)
- Data del documento
- Tipologia del documento (prosa/poesia)
- Se il documento appartiene a un’edizione di riferimento per titolo della raccolta/edizione (es. Documenta Indica, Sinica Franciscana)
- Genere (es. Ars Grammatica, Epistolae, Itinera et Relationes)
- Geographic reference: è un’indicazione geografica molto generica (es. Cina, India etc.) che riguarda l'intero documento
- Language: lingue utilizzate nel documento (la percentuale di utilizzo di ogni lingua è segnalata nel Tei/Header del documento XML)
2. Visualizzazione del documento
Accesso
Nel pannello Document List si accede al documento cliccando la freccia accanto al titolo:

Nei pannelli Search e Browse si accede alla visualizzazione tramite l'icona documento:

Visualizzazione

Il pannello Info mostra alcuni metadati essenziali, mentre il pannello Menu permette di modificare la visualizzazione del documento (suddivisione pagine, sottolineatura dei tag, sfondo del documento) e di attivare il download in formato TXT, XML e PDF.
L’intestazione di ogni documento riporta il titolo, l’autore, la data di nascita e morte dell’autore, e l’edizione di riferimento. Autore e edizioni hanno di norma, se esistente, un link a VIAF e WorldCat.
Il documento ha dei tag: passando sulle parole sottolineate, una finestra pop-up descrive la tipologia del tag (persona, luogo, data) e ne mostra una versione normalizzata. Cliccando sul tag può essere attivo, dove è stato individuato, un collegamento a



3. Informazioni sul documento
I metadati relativi alla risorsa sono disponibili su ciascun documento cliccando, nei pannelli Browse e Search, sull’icona Info:

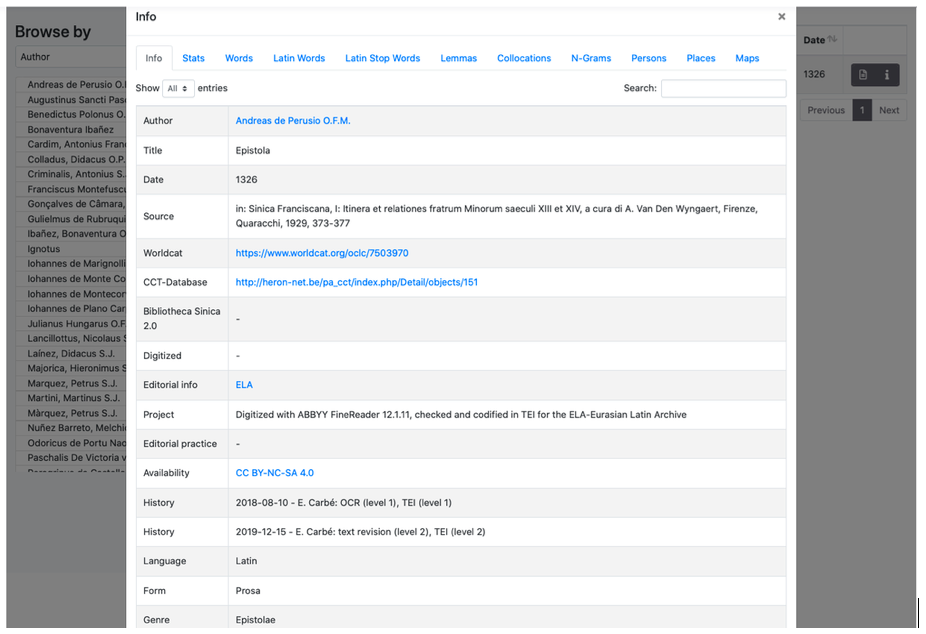
Vengono indicati autore, titolo, data, risorsa di riferimento con un link a Worldcat e, dove presenti, collegamenti a schede di CCT - The Chinese Christian Texts Database e Bibliotheca Sinica 2.0.
Se la risorsa è riprodotta e disponibile online, il link è visualizzabile alla voce “Digitized”.
Le informazioni riguardanti il progetto e le pratiche editoriali sono alle voci Project e Editorial Practices.
Availability indica la licenza con la quale viene rilasciato il documento. I testi pubblicati da ELA hanno la licenza Creative Commons BY-NC-SA 4.0. Documenti provenienti da altri progetti, archivi, biblioteche digitali (es. ALIM, Corpus Corporum, Gutenberg Project) mantengono la licenza originaria e potrebbero in alcuni casi essere soggetti a Copyright.
La voce History dà conto della storia del documento e dei responsabili delle modifiche. I documenti di ELA sono sottoposti a un controllo della qualità tramite l'assegnazione di un punteggio (1-3) sia sull'affidabilità di trascrizione sia sulla codifica XML/TEI.
- Qualità della trascrizione: un documento a cui è stato assegnato il punteggio 3 è stato revisionato almeno da tre editor ed è considerato altamente affidabile. Il livello 2 indica che il testo è stato verificato da un solo editor. Il livello 1 presenta un testo che verosimimente può avere più di un refuso. ELA non pubblica documenti con OCR non verificati a meno che non siano già stati messi a disposizione online da altre biblioteche digitali: in questo unico caso il punteggio assegnato per il livello di affidabilità del testo è 0.
- Per la qualità di marcatura TEI, il punteggio massimo 3 viene dato solo dopo una revisione manuale delle marcature semantiche (nomi di luogo e di persona, date), il punteggio 2 indica che la marcatura del testo è stata effettuata/corretta manualmente, e che le marcature semantiche sono state affidate al sistema automatico di Retag di ELA-Tools. Il punteggio 1 indica una non ottimale marcatura strutturale e semantica.
4. ELA Tools
ELA ha progettato alcuni strumenti disponibili su GitHub, che vanno da tool per estrarre informazioni di file XML e effettuare delle operazioni automatiche di marcatura TEI a Jupyter notebooks da utilizzare per la pulizia e la normalizzazione dei testi e per l'analisi di documenti. Lo strumento principale, basato su CLTK e NLTK, è stato integrato alla piattaforma ELA per ottenere statistiche e informazioni linguistiche/semantiche sui singoli documenti.
4.1 Statistiche e analisi sul documento
Dal pannello info è possibile accedere alle sezioni riguardanti le statistiche e le analisi del documento:
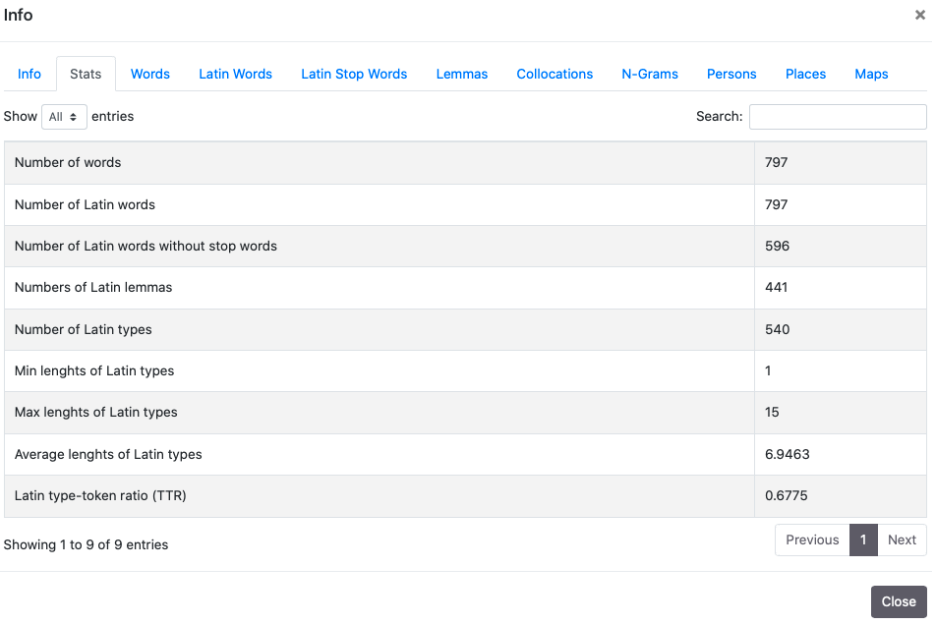
- Stats
- Numero di parole e numero di parole latine contenute nel documento (se il documento non è multilingua ovviamente il numero coincide)
- Numero di parole latine meno il numero di stop words
- Numero di lemmi latini identificati dal lemmatizzatore di CLTK
- Numero di type in lingua latina
- Massima/minima/media lunghezza dei type in lingua latina
- Type/Token Rario (TTR)
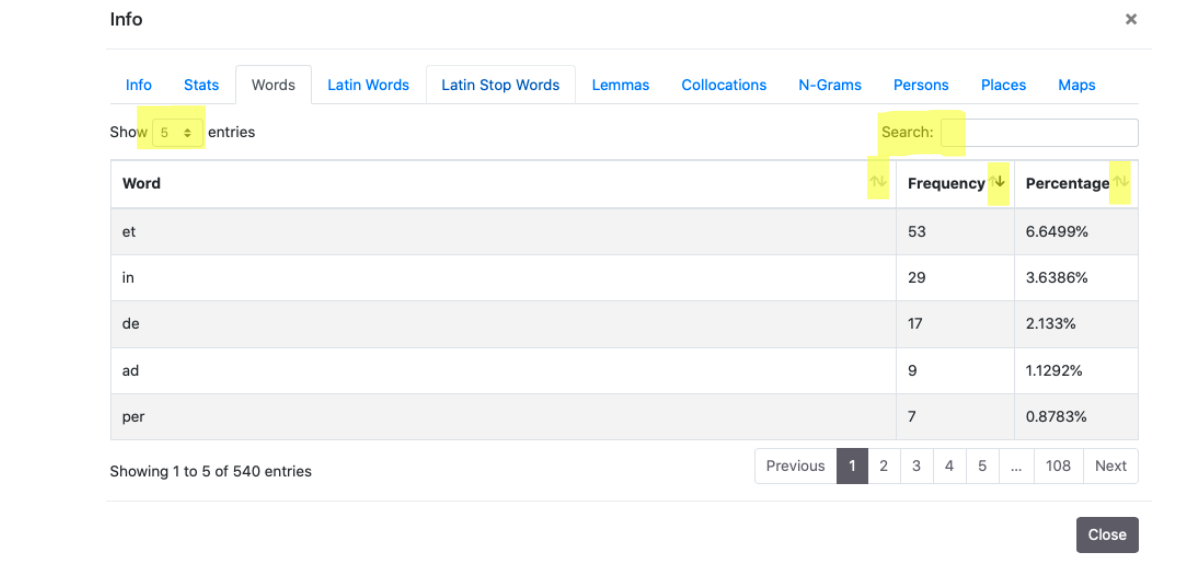
2. Words e Latin Words
In queste due schede si presentano le liste di frequenze del testo collegate a type, che si possono visualizzare in ordine alfabetico (Word), di frequenza (Frequency) e di frequenza relativa (Percentage) crescente/descrescente. Le due schede mostrano di default le prime cinque occorrenze in ordine di frequenza decrescente: è possibile modificare la visualizzazione con il menu a tendina "Show entries" e sfruttare il modulo "Search" per cercare parole o porzioni di parole. Se il documento non è multilingua le due schede sono identiche.
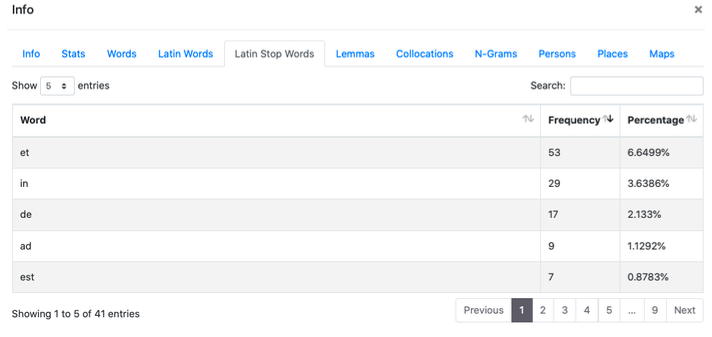
3. Latin Stop Words
In questo pannello, che funziona come i due precedenti, si presenta un indice di frequenze delle seguenti stop words: ab, ac, ad, adhuc, aliqui, aliquis, an, ante, apud, at, atque, aut, autem, cum, cur, de, deinde, dum, ego, enim, ergo, es, est, et, etiam, etsi, ex, fio, haud, hic, iam, idem, igitur, ille, in, infra, inter, interim, ipse, is, ita, magis, modo, mox, nam, ne, nec, necque, neque, nisi, non, nos, o, ob, per, possum, post, pro, quae, quam, quare, qui, quia, quicumque, quidem, quilibet, quis, quisnam, quisquam, quisque, quisquis, quo, quoniam, sed, si, sic, sive, sub, sui, sum, super, suus, tam, tamen, trans, tu, tum, ubi, uel, uero, unus, ut.
4. Lemmi
ELA utilizza il lemmatizzatore di CLTK (Backoff Method). Per l'utilizzo del lemmatizzatore Lexicon (lexicon.unisi.it) è possibile scaricare il corpus ELA in formato txt da GitHub.
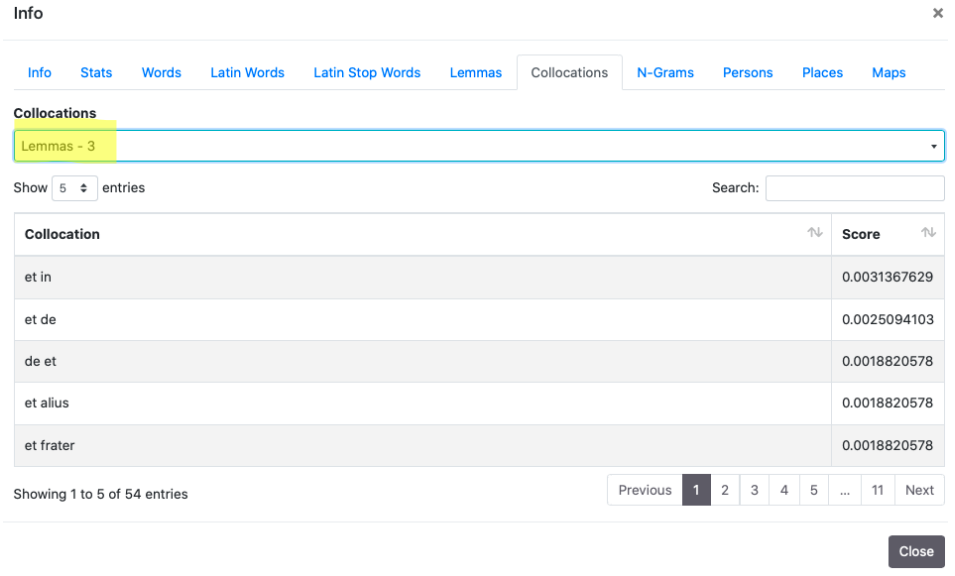
4. Collocations
Si possono eseguire ricerche con un range da 1 a 5 sia sulle parole che sui lemmi, utilizzando il modulo "Search" e verificando lo score attribuito. Per la documentazione si rimanda alla sezione dedicata di NLKT.
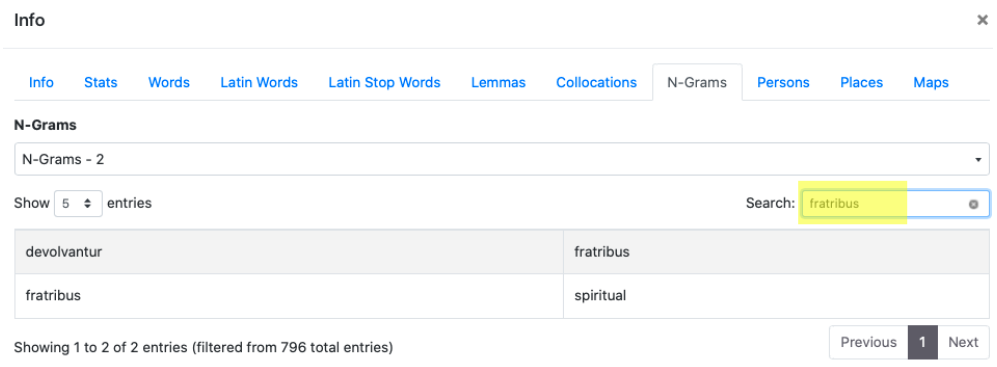
4. N-grams
Gli N-grammi (da 2 a 5) mostrano le sequenze di parole, che possono essere ricercate a partire dal modulo "Search"
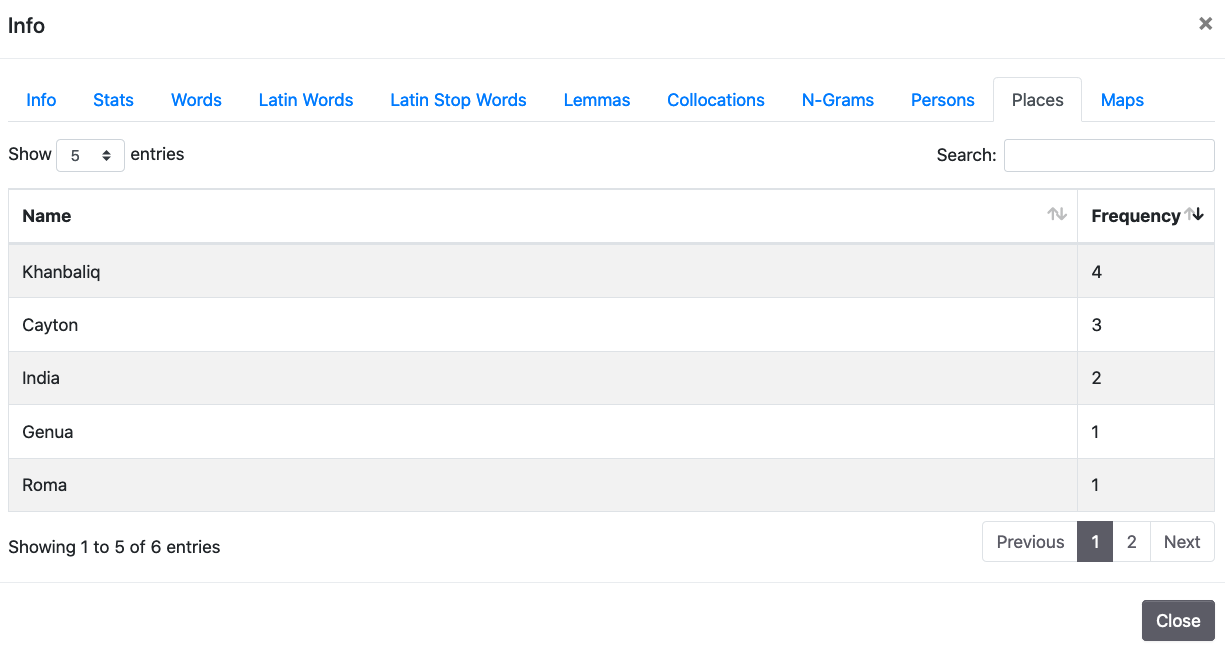
5. Person/Place
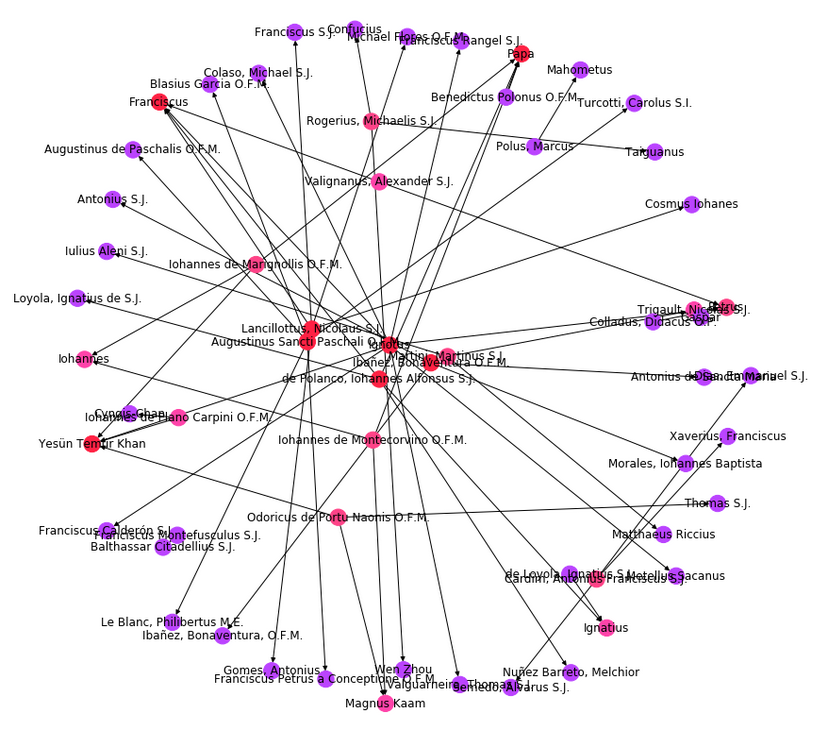
In queste due schede vengono presentate le frequenze dei nomi di persona e di luogo presenti nel testo. Si consideri che la lista potrebbe non essere completa per i documenti che non hanno il livello TEI 3.
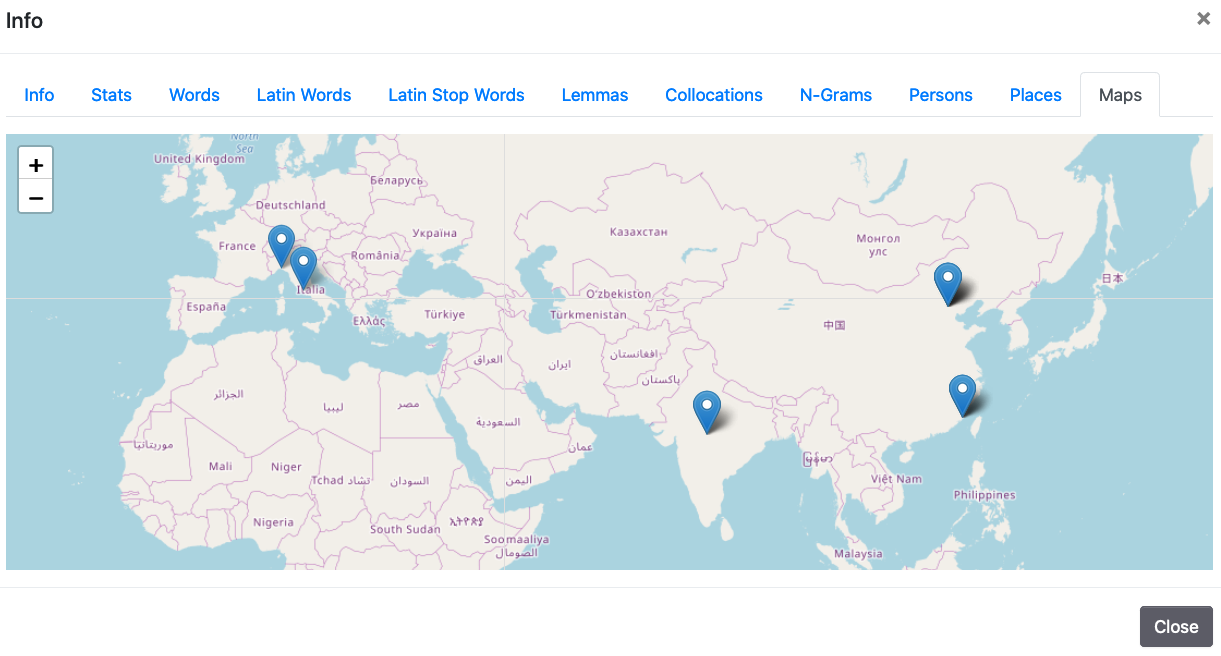
6. Maps
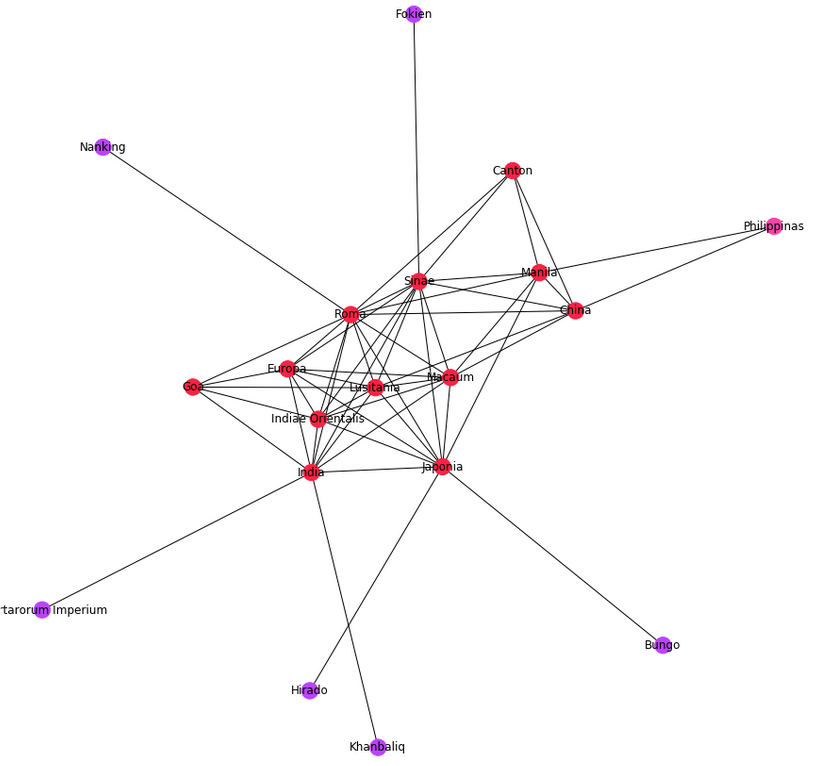
La mappa, basata su Leaflets, riporta la geolocalizzazione di tutti i nomi di luogo che sono stati identificati con Pleiades e GeoName. Come per le schede Person/Place, anche in questo caso va considerato che le informazioni date potrebbero essere non complete rispetto ai luoghi effettivamente citati nel documento. Cliccando sui luoghi segnati nella mappa, è possibile visualizzare il nome normalizzato e la forma o le forme che si presentano nel testo.
4.3 Statistiche e analisi di corpora e subcorpora
4.4 Altre analisi
Per lavorare sull'intero corpus o su un subcorpus di ELA è possibile anche utilizzare lo strumento GlobalStats disponibile e documentato su GitHub a questo indirizzo, insieme con il relativo Jupyter notebook, dove sono presenti alcuni esempi di Cloud di parole e di Network Analysis.